
Omnious에서 사용하는 k8s의 workload 중 CronJob과 이를 자동으로 증설하기 위한 방안을 한가지 사례를 통해 얘기해보겠습니다.
kubernetes Workload - CronJob
CronJob은 백업, 리포트 생성 등의 정기적 작업을 수행하기 위해 사용됩니다. 각 작업은 무기한 반복되도록 구성해야 합니다(예: 1일/1주/1달마다 1회). 작업을 시작해야 하는 해당 간격 내 특정 시점을 정의할 수 있습니다.
kubernetes 버전 1.21에서 CronJob이 GA로 승격되었습니다. 해당 버전부터는 batch/v1 CronJob을 지원하지 않습니다. 시간 기반의 스케줄에 따라 CronJob을 이용하여 Job을 실행 할 수 있고,주기적이고 반복적인 작업들을 생성하는데 유용합니다.
cronjob.yaml 예시
이 CronJob 매니페스트 예제는 현재 시간과 hello 메시지를 1분마다 출력합니다.
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
CronJob은 일정의 실행시간 마다 한번의 Job 오브젝트를 생성합니다.
CronJob 적용 사례
서비스를 운영하면서 다양한 유형의 데이터(유저 정보, 분석 데이터 등)가 존재하고 각 데이터의 특성을 고려하여 가공하거나 정제하는 작업을 할 수 있도록 데이터 파이프라인을 설계 해야 합니다.
Omnious에서는 pipeline을 통하여 이미지 관련 메타 데이터와 model 결과를 저장하고 이를 서비스에 제공하고 있는데, 일부 데이터의 경우 서비스에 제공하기 위해 매일 주기적으로 수집/가공하는 단계를 거치고 있습니다.
아래에는 data pipeline 설계시 필요한 요구사항입니다.
- 특정 job이 완료 된 이후 연결된 pipeline이 데이터를 처리 할 수 있도록 한다.
- job은 kst 00:00 시에 시작하여 kst 05:00 이전에 모든 데이터 처리를 완료한다.
- 데이터는 증가하며 이를 안정적으로 수용할 수 있어야 한다.
- 각각의 batch job이 안정적으로 처리되어야 하며 fail시 retry 및 알람을 통해 작업자가 인지 할 수 있도록 한다.
위의 요구사항을 고려하여 설계시 정의한 항목입니다.
- 데이터는 group단위로 묶는다.
- 각 group은 하나의 CronJob에 mapping한다.
즉 하나의 CronJob은 하나의 Data Group을 처리하는 형태로 설계해보았습니다.
그림으로 표현하면 아래와 같습니다.
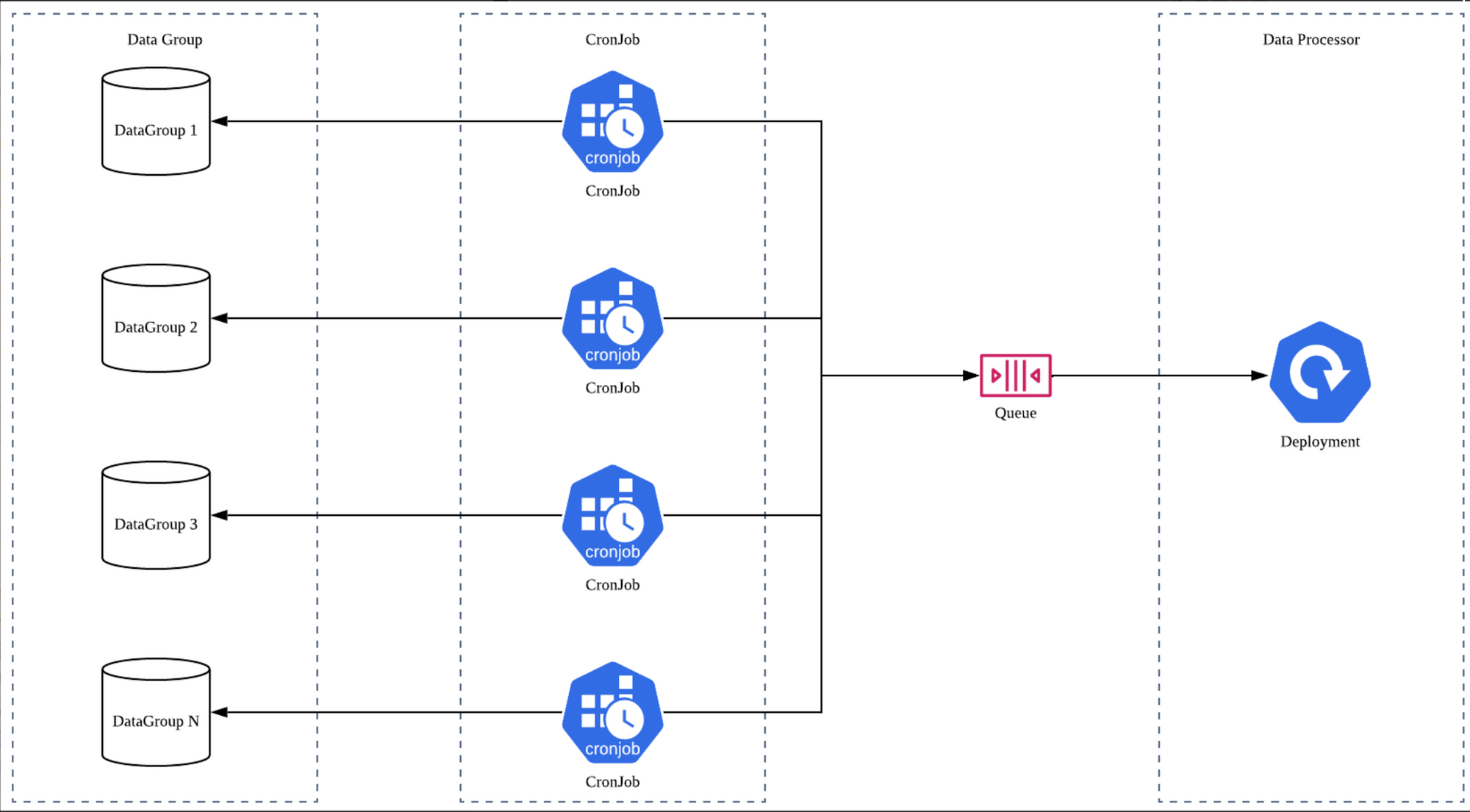
1000만개의 데이터가 존재한다고 가정하고 각각의 Job이 제한된 시간안에 처리 할 수 있는 데이터의 양이 100만개라고 가정했을때 이를 10개의 그룹으로 나눕니다.
위와 같은 설계는 몇가지 해결해야 하는 것들이 있습니다.
- 데이터가 100만개 증가하여 1100만개가 되었다고 가정했을때, Job의 수용량은 100만이고, 이미 10개의 CronJob 으로는 수용량 1000만개를 채운 상태입니다. 새로운 CronJob생성이 필요합니다.
- 증가한 데이터의 경우에도 새로운 Group 할당이 필요합니다.
- CronJob을 yaml로 관리하고 있는데 CronJob을 여러개 배포하고 관리하는 일에 많은 resource가 필요합니다. 일례로 환경변수의 값을 각각의 CronJob 마다 다르게 적용하고 있는데 yaml 파일에 이런 점을 반영해야 하고, Cronjob 코드를 개선하는 경우 이를 인프라에 배포된 모든 Cronjob yaml에 repo version을 업데이트 해야 합니다.
Kubernetes Python Client
데이터가 증가됨에 따라 CronJob 증설을 자동화하기 위해서 아래와 같이 목표를 설정했습니다.
- 증가된 데이터에 대해서 Group을 할당하고 CronJob 증설이 필요한 경우 CronJob을 자동으로 생성하도록 하자.
- yaml 파일은 cdk8s를 이용하여 코드로 관리하자.
yaml 파일을 관리하는 부분은 차후에 cdk8s를 활용한 python application 배포 포스트에서 다루겠습니다.
kubernetes에 CronJob 증설을 자동화 하기 위해서는 cluster에 접근할 수 있는 인증이 필요하고, 이를 가능하게끔 kubernetes는 제공하고 있습니다.
Kubernetes Python Client에 대해서 간단히 소개드리겠습니다.
Kubernetes Client Library는 kubernetes API를 사용하기 위한 클라이언트 library에 대한 개요를 포함하고 있습니다. Kubernetes REST API를 사용해 application을 작성하기 위해 API 호출 또는 요청/응답을 직접 구현할 필요가 없습니다. 사용하고 있는 프로그래밍 언어를 위한 client-library를 사용하면 됩니다.
클라이언트 라이브러리는 대체로 인증과 같은 공통의 태스크를 처리합니다.. 대부분의 클라이언트 라이브러리들은 API 클라이언트가 kubernetes 클러스터 내부에서 동작하는 경우 인증 또는 kubeconfig 파일 포맷을 통해 자격증명과 API 서버 주소를 읽을 수 있게 kubernetes 서비스 어카운트를 발견하고 사용할 수 있습니다.
kubeconfig 파일 예시
apiVersion: v1
kind: Config
preferences: {}
clusters:
-cluster:
name: development
-cluster:
name: scratch
users:
-name: developer
-name: experimenter
contexts:
-context:
name: dev-frontend
-context:
name: dev-storage
-context:
name: exp-scratch
공식 지원 Kubernetes client library
| language | client library |
|---|---|
| dotnet | https://github.com/kubernetes-client/csharp |
| Go | https://github.com/kubernetes/client-go/ |
| Haskell | https://github.com/kubernetes-client/haskell |
| Java | https://github.com/kubernetes-client/java |
| Javascript | https://github.com/kubernetes-client/javascript |
| Python | https://github.com/kubernetes-client/python/ |
이외에도 커뮤니티에 의해 관리되는 Client library들도 있습니다만 이글에서는 다루지 않겠습니다.
위의 공식지원 표를 기준으로 Kubernetes client library가 다양한 언어를 지원한다는걸 알 수 있습니다.
Omnious에서는 주로 python을 사용하고 있기 때문에, Kubernetes Python Client의 setup과 이후 과정에 대해 설명드리겠습니다.
PyPI를 이용한 설치
pip install kubernetes
Example Code
from kubernetes import client, config
# Configs can be set in Configuration class directly or using helper utility
config.load_kube_config()
v1 = client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\\t%s\\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
config.load_kube_config()를 통해 인증을 획득한 시점에서 kubectl, kubeadm과 같은 커맨드 라인 도구를 통해 cluster 관련 작업을 수행 할 수 있습니다. 위의 코드는 pod에 namespace목록을 조회하는 코드입니다. 이어서 크론잡을 배포하는 방법을 소개하겠습니다.
kubernetes를 처음 접하게 되면 다양한 어려움이 존재하지만 그중에 한가지를 꼽아보면 복잡한 kubernetes를 제어하고자 할 때 너무 많은 기능과 명령어들이 존재하여 정보의 바다에서 헤엄치는 느낌이들곤 합니다.
kubernetes client의 경우 다음과 같은 문서를 제공하고 있습니다.
위 문서의 예제 코드를 참고하여 상대적으로 쉽게 구현 할 수 있습니다.
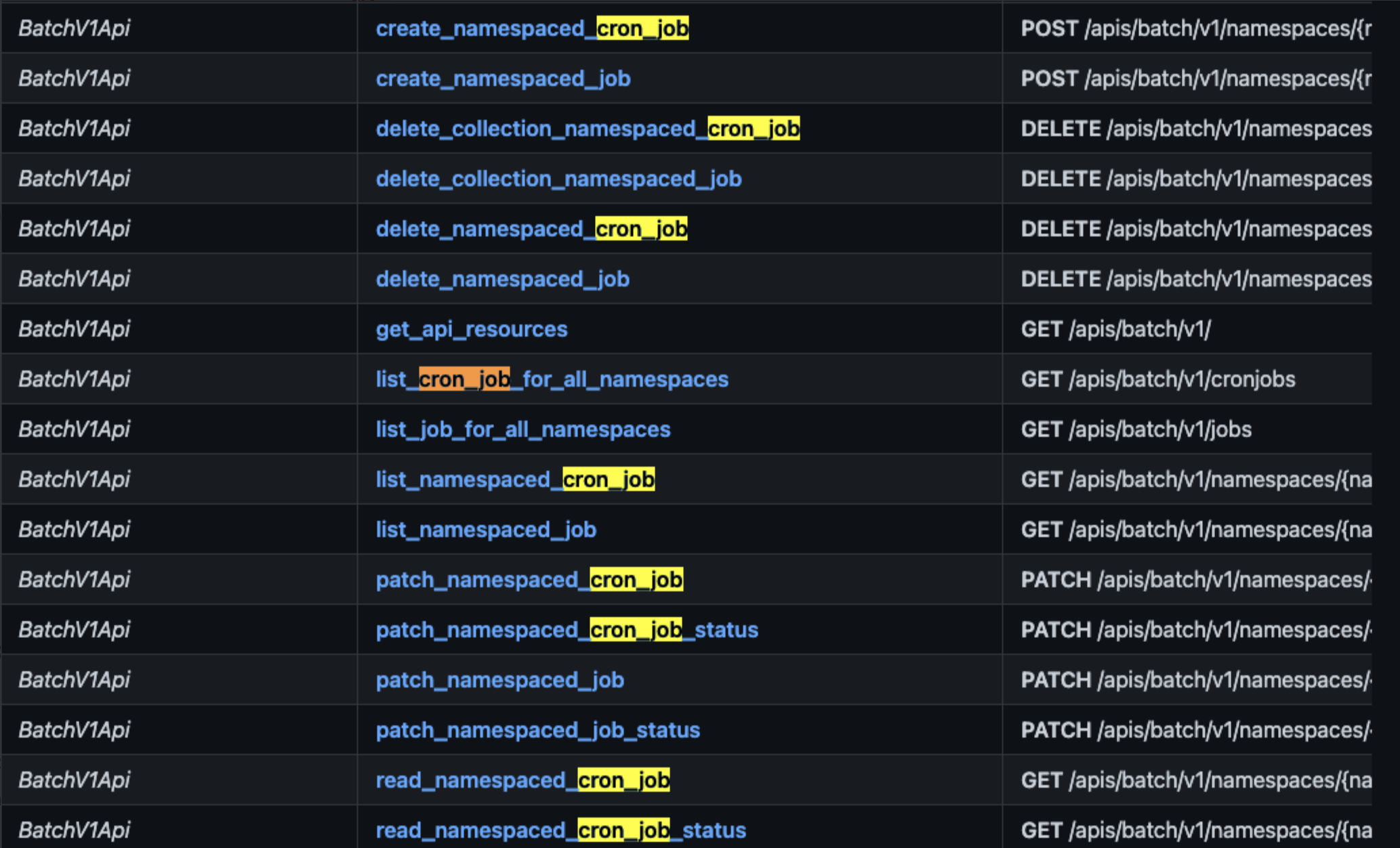
create_namespaced_cron_job 예시
from __future__ import print_function
import time
import kubernetes.client
from kubernetes.client.rest import ApiException
from pprint import pprint
configuration = kubernetes.client.Configuration()
# Configure API key authorization: BearerToken
configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# configuration.api_key_prefix['authorization'] = 'Bearer'
# Defining host is optional and default to <http://localhost>
configuration.host = "<http://localhost>"
# Enter a context with an instance of the API kubernetes.client
with kubernetes.client.ApiClient(configuration) as api_client:
# Create an instance of the API class
api_instance = kubernetes.client.BatchV1Api(api_client)
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = kubernetes.client.V1CronJob() # V1CronJob |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
dry_run = 'dry_run_example' # str | When present, indicates that modifications should not be persisted. An invalid or unrecognized dryRun directive will result in an error response and no further processing of the request. Valid values are: - All: all dry run stages will be processed (optional)
field_manager = 'field_manager_example' # str | fieldManager is a name associated with the actor or entity that is making these changes. The value must be less than or 128 characters long, and only contain printable characters, as defined by <https://golang.org/pkg/unicode/#IsPrint>. (optional)
field_validation = 'field_validation_example' # str | fieldValidation determines how the server should respond to unknown/duplicate fields in the object in the request. Introduced as alpha in 1.23, older servers or servers with the `ServerSideFieldValidation` feature disabled will discard valid values specified in this param and not perform any server side field validation. Valid values are: - Ignore: ignores unknown/duplicate fields. - Warn: responds with a warning for each unknown/duplicate field, but successfully serves the request. - Strict: fails the request on unknown/duplicate fields. (optional)
try:
api_response = api_instance.create_namespaced_cron_job(namespace, body, pretty=pretty, dry_run=dry_run, field_manager=field_manager, field_validation=field_validation)
pprint(api_response)
except ApiException as e:
print("Exception when calling BatchV1Api->create_namespaced_cron_job: %s\\n" % e)
위 예시를 통하여 코드를 수행하면 지정한 namespace에 cron_job이 생성됩니다. 한가지 허들이 될 수 있는 부분은 api_response = api_instance.create_namespaced_cron_job(namespace, body, pretty=pretty, dry_run=dry_run, field_manager=field_manager, field_validation=field_validation) 에서 body를 정의하는 부분인데 kubernetes.client.V1CronJob() 을 통하여 body의 기본 적인 spec은 정의되어 있고 이를 요구사항에 맞게 custom 진행합니다.
Sample Code 실습
위의 예제를 토대로 간단히 1분마다 hello 메시지를 출력하는 간단한 CronJob을 cluster에 배포해보도록 하겠습니다.
kubeconfig file download
Omnious에서는 Cluster를 관리하기 위해 Rancher를 사용하고 있습니다. (https://rancher.com/)
Rancher는 kubernetes 클러스터를 관리하기 위한 여러가지 도구들을 제공하고 있습니다.
Kubeconfig File을 클릭하여 kubeconfig file을 저장합니다.
kubeconfig file 예시 https://kubernetes.io/ko/docs/concepts/configuration/organize-cluster-access-kubeconfig

Kubeconfig를 이용한 클러스터의 pod 목록 조회
아래와 같이 매우 간단한 코드로 pod목록을 조회 할 수 있습니다.
# Configs can be set in Configuration class directly or using helper utility
kube_config.load_kube_config(config_file=KUBECONFIG_FILE)
v1 = client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\\t%s\\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Hello CronJob 배포
Hello Cronjob.yaml 파일
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
CronJob 배포 코드
apps_v1 = client.BatchV1beta1Api()
with open(CRONJOB_FILE, "r") as f:
template = yaml.safe_load(f)
namespace = 'test-namespace'
try:
api_response = apps_v1.create_namespaced_cron_job(namespace, template)
pprint(api_response)
except ApiException as e:
print("Exception when calling BatchV1Api->create_namespaced_cron_job: %s\\n" % e)
위 코드가 정상적으로 수행되어 CronJob이 생성되면 아래와 같은 결과를 받습니다.
이제 rancher에서 배포된 CronJob을 확인해보겠습니다.
test-namespace에 정상 배포된 CronJob

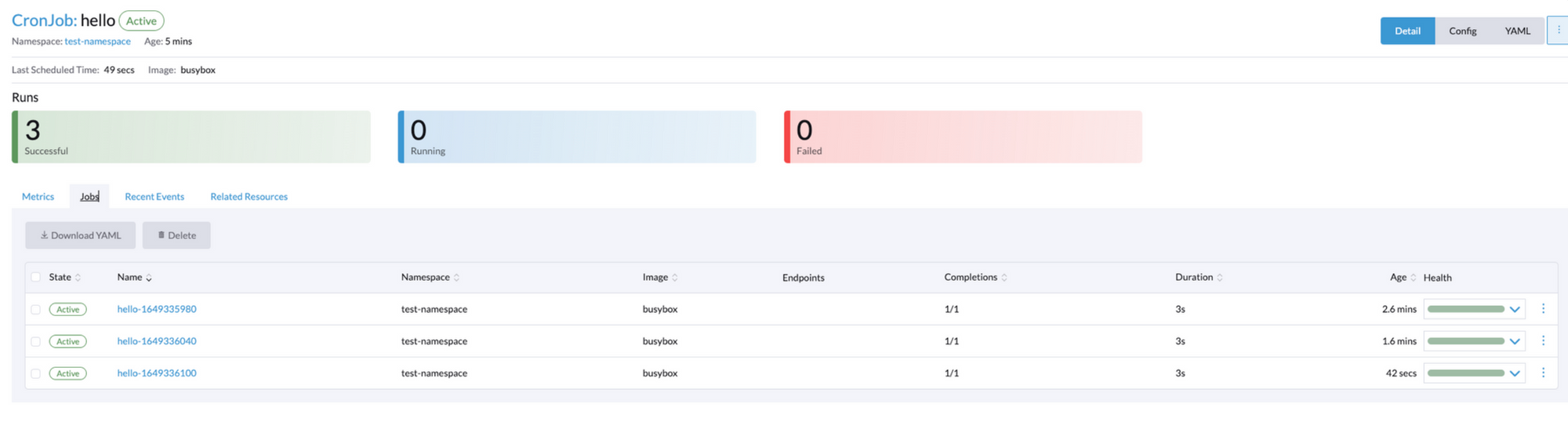
pod 로그

이상으로 CronJob 배포 실습을 완료했습니다.
Omnious Cronjob Controller
kubernetes-client를 이용한 data group 및 Cronjob 자동 증설을 적용한 도식을 간단히 표현하면 다음과 같습니다. 간단히 Omnious Cronjob Controller로 명명한 Job이 수행되면 data를 스캔하고 필요시 CronJob을 증설하도록 되어 있습니다.
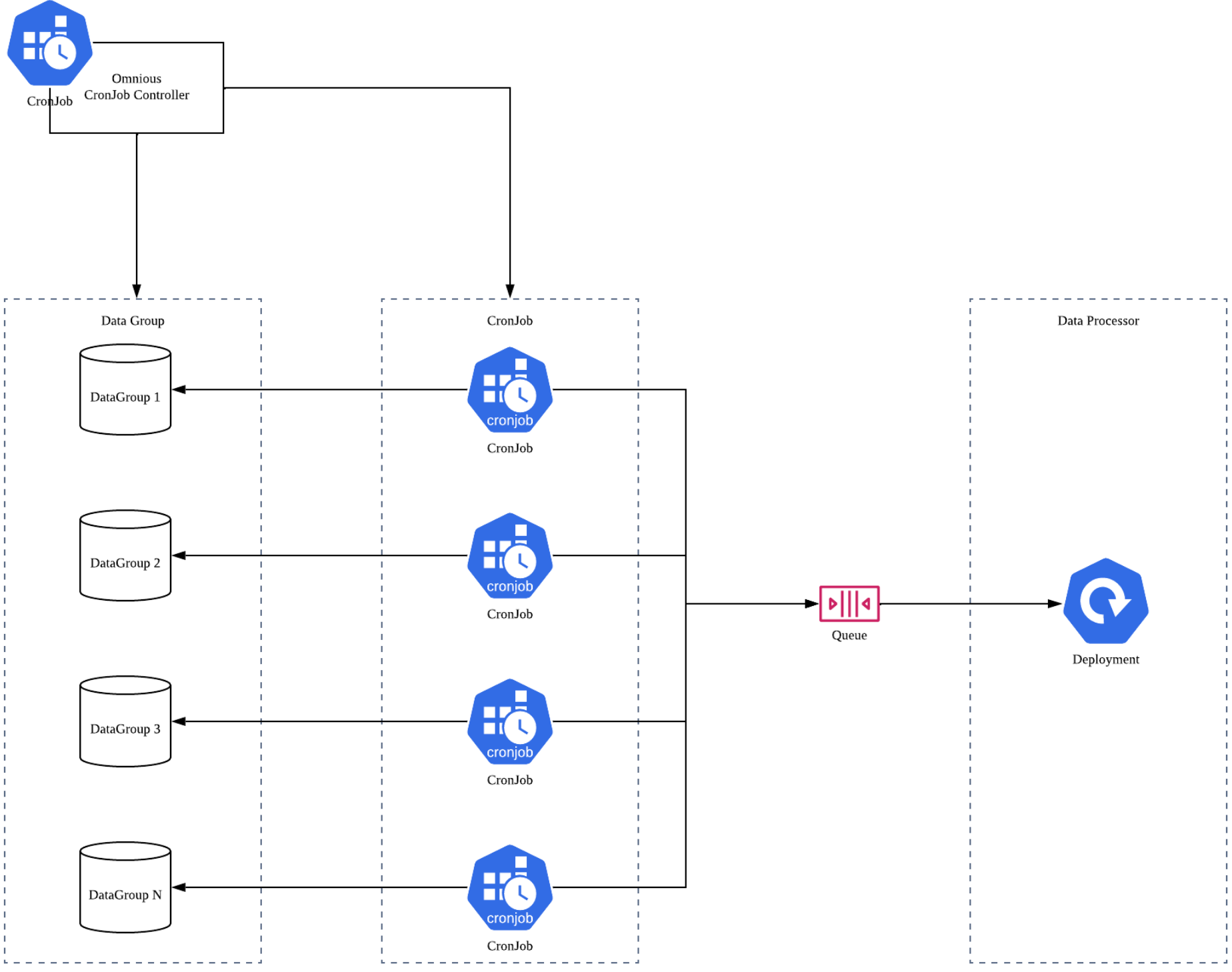
글을 작성하며 kubernetes 문서를 읽어보고 설계에 대한 도식을 그려보며 아쉬운 점들이 보입니다. 위 도식에서는 Data Group을 관리하는 부분, CronJob을 추가로 생성하는 Controller가 하나의 Job에서 모두 처리하고 있습니다.
이를 개선해본다면 Data 관리를 위한 기능과 CronJob을 증설하는Controller를 분리하여 CronJob Controller는 CronJob을 관리하고 더 나아가 자원을 효율적으로 관리하도록 발전시키면 좀 더 좋을 것 같습니다.





